
Foundations of Transformer Language Modeling
0. Introduction: the mathematical definition of language modeling
Natural language can be viewed as a discrete sequence generated from a finite vocabulary :
The goal of a language model is to define the probability distribution
where .
1. The decoder-only Transformer
Modern language models such as GPT and LLaMA typically use the decoder-only Transformer, because it naturally matches autoregressive prediction.
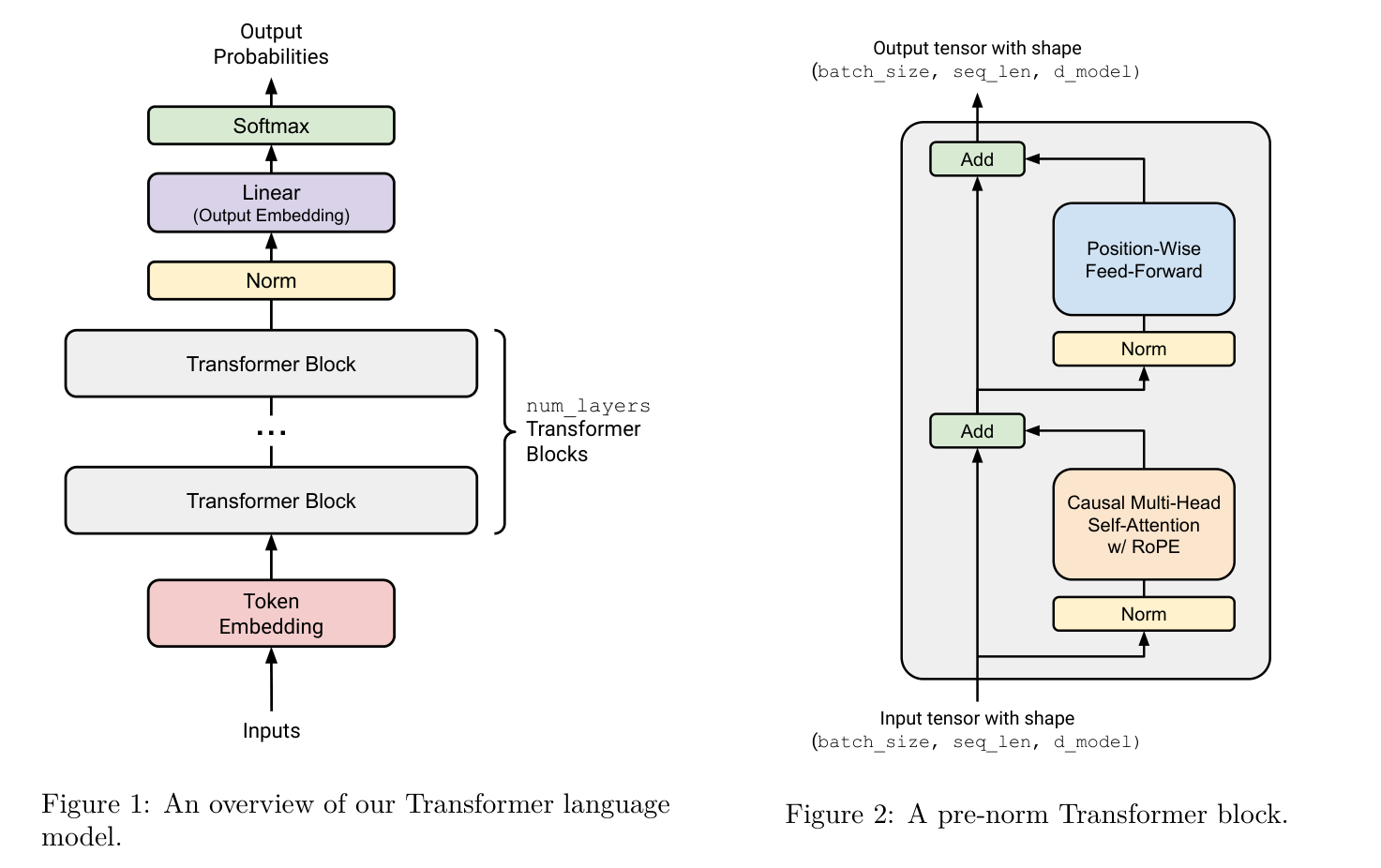
1.1 Input representation: token embedding + position embedding
Each token id is first mapped into a vector:
where is the embedding matrix.
Because attention by itself does not encode position, we add a positional vector :
2. The Transformer block
Each Transformer layer contains two main parts:
- masked self-attention
- feed-forward network
with residual connections and layer normalization.
2.1 Linear projections to Q, K, and V
Let the input to a layer be
We compute
Intuitively:
- Q asks what information I want;
- K describes what kind of information each token offers;
- V carries the actual content that will be aggregated.
2.2 Scaled dot-product attention
The raw similarity matrix is
2.3 Causal masking
For language modeling, token must not see the future. So we apply a causal mask:
2.4 Softmax attention
The normalized attention matrix is
2.5 Information aggregation
The output at position is
3. Multi-head attention and FFN
Instead of using a single attention mechanism, the model splits the representation into several heads. Each head can focus on a different type of dependency.
After attention, each token representation passes through a position-wise feed-forward network:
4. Final remarks
If I had to summarize the whole picture in one sentence, it would be this:
A decoder-only Transformer is a machine that repeatedly decides what each token should attend to, then updates the representation accordingly, while never looking into the future.